My First Production Disaster ( A Debug tale working with AWS )

How it started:
It was 5:00 pm, 1st of November, and I was off work, celebrating "Karnataka Rajotsava" a regional festival in Bangalore, India. I was about to step out to enjoy the evening when my phone suddenly rings with caller ID highlighting "Prod Escalation Team"...
As I pick up the phone, I hear multiple voices, focusing on one voice I hear vaguely "None of the customers can access the user interface" and till today that gives me *** goosebumps ***.
#Introduction
Before I continue, a short introduction on myself - I work as Cloud Engineer with an MNC which manufactures Networking devices such as "Switch/Routers/APs etc..." and have a unified user interface to monitor all the devices. I primarily focus on UI architecture and its related workflows.
#Problem
Suddenly all the end users located in the Europe region were not able to access the UI. As we serve multiple clients, the production clusters are spread across the world ( America / Asia Pacific / Europe ).
Also, shockingly, neither this issue was seen in any other region running the same deployment tag nor it was seen in any QA clusters.
Note: Everything was working as expected when the cluster was upgraded a few months back, no recent change had been pushed.
#Debugging
The logs, "har" files and screenshots were all collected from end users.
On checking the "har", we noticed one request which was returning the status code "0", which basically means the request was canceled before reaching the server.
Brief working of UI -
We load our UI static content ( .json / *.js ) files from CDN hosted at AWS using Cloudfront service.
On the initial load of the UI we hit the CDN servers to fetch the latest content.
On debugging further we noticed a CORS error in one of the screenshots of the browser console. This was linked to the file which was failing with status code "0"
Note: This issue was happening only in one specific region and we were not able to reproduce this locally or in any QA clusters, also there were no issues when the cluster was upgraded a few months back.
As these files were fetched from CDN servers hosted by AWS, the first instinct that comes to mind is "something is wrong with AWS", as we are a major client of AWS, we have instant support. We went ahead and raised the ticket.
Post AWS team checking the issue, we realised logging for CDN servers was disabled for our buckets. So AWS team couldn't do much at the moment. They suggested invalidating the cache of the CDN servers forcing the content to be pulled again at the edge.
Temporarily that resolved the issue, the exact root cause was still unknown, it was hinted that we were reaching more than 1000 new file paths (PFA), hence it was causing issues. Which did not make sense to me.
A few days later, this issue was seen again. We put on our debugging hats and got into finding the root cause instead of directly assigning it to AWS -
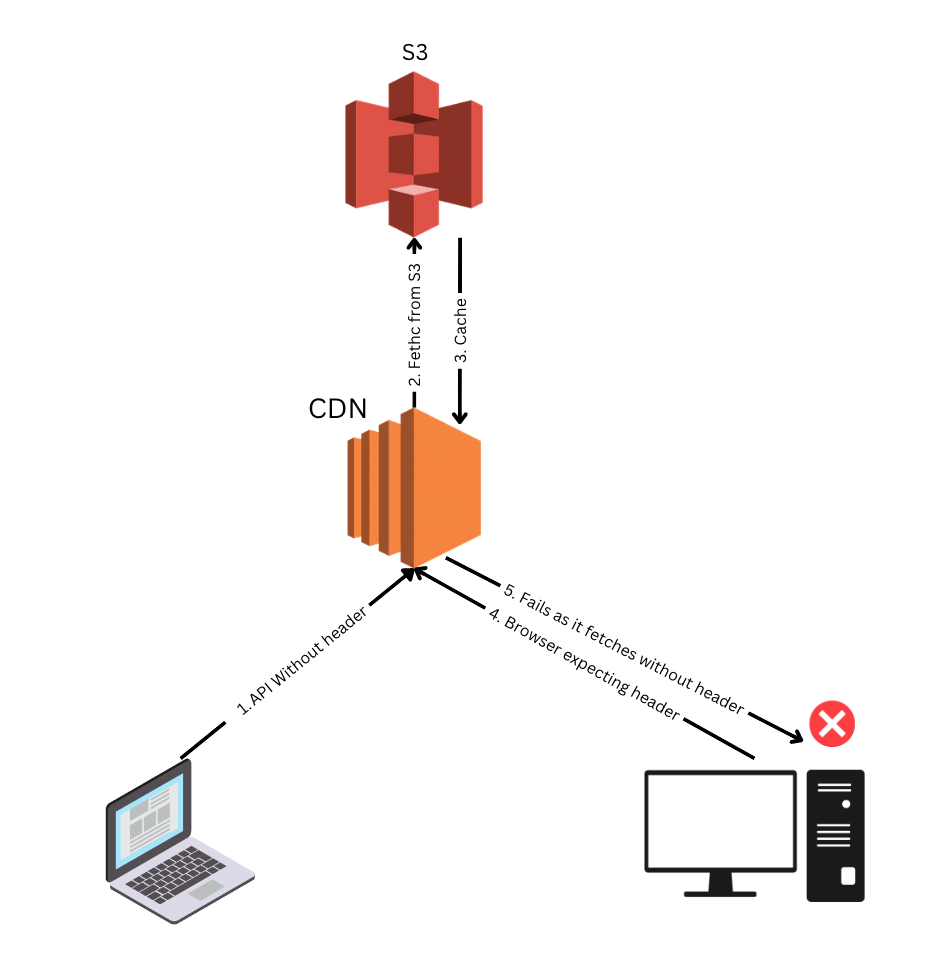
This time we focused on inspecting the headers of the failing API call and comparing the same request on a working cluster.
We noticed certain response headers were missing in the failing API. On checking further it looked like these headers were added by CloudFront but were missing in the failing request.
On googling those missing headers, found out the CDN was misconfigured to restrict some headers. On applying the configuration we noticed the issue was resolved.
Access-Control-Request-Headers Access-Control-Request-Method OriginLinks related to the below issue –
#Root-Cause & Learnings
Cloudfront was caching the assets which did not have the required response headers. As these servers are geographically separated, certain locations were only affected.
This could have happened if a user accessed the particular file from the command line directly or from a browser with security options disabled such that it does not check for the headers.
Check out - https://stackoverflow.com/a/42028071
Post that when a user accesses the UI from browsers such as Chrome, and Firefox which checks for these response headers, and finds it missing it cancels the request hence "status code 0" and shows the CORS error.
PS: #DebuggingFeb